Market Sentiment Analysis
In the fast-paced world of crypto trading, staying informed is key to making smart decisions. Market sentiment plays a crucial role in driving crypto prices, as positive sentiment can spark buying trends while negative sentiment often leads to sell-offs

Foreword
As part of our research program at AVNU, we had the pleasure to welcome, last semester, Xingyue Zhang. Xingyue is a master student in Data Science from Ecole Polytechnique Federal de Lausanne (EPFL) with an undergraduate background in investment finance.
At AVNU, she brillantly led a new project on market sentiment analysis which is part of our on-going focus on AI in DeFi and below we are proud to present the result of her work that we believe can serve the community.
Background and Motivation
In the fast-paced world of crypto trading, staying informed is key to making smart decisions. Market sentiment plays a crucial role in driving crypto prices, as positive sentiment can spark buying trends while negative sentiment often leads to sell-offs.
At AVNU, we are committed to providing the best possible user experience by equipping our users with tools that offer deeper market insights. One such tool we are building is a sentiment analysis system that analyzes the most recent text data from multiple media sources to ensure up-to-date insights. These media sources include news articles from various crypto platforms, tweets, Reddit discussions, and so on.
To achieve this, we use advanced Natural Language Processing (NLP) techniques and Large Language Models (LLMs), including BERT-based and GPT-based models. These technologies allow us to interpret the nuances of human language, enabling accurate sentiment analysis across diverse media sources. By transforming unstructured text data into measurable insights, we aim to provide traders with information about the mood and trends in the crypto market.
In a nutshell, what we are doing is labeling text data with sentiment and aggregating the scores to derive a final sentiment score for each cryptocurrency.
Addressing the Data Labeling Challenge
To train or fine-tune advanced language models for cryptocurrency sentiment analysis, having a high-quality labeled dataset is essential. These datasets are the foundation that allows models to learn and accurately predict sentiment for new, unseen data.
A labeled dataset typically consists of text data paired with sentiment labels. For example, a labeled dataset might look like this

Each text snippet is associated with a sentiment label, often categorized as bullish (positive), bearish (negative), or neutral.
However, in the field of cryptocurrency, obtaining reliable labeled datasets for text data presents a significant challenge. Many existing studies in the crypto space attempt to address this by using naive tools like VADER or TextBlob to label text data. These are rule-based methods that rely on predefined word lists and basic heuristics to assign sentiment scores. They often fail to capture the complexities and nuances of crypto-related discussions, such as domain-specific terminology, evolving slang, and sarcasm. Moreover, they do not consider the surrounding context of a word, which is critical in interpreting the meaning of text accurately.
The phrase “garbage in, garbage out” perfectly applies here. When researchers use VADER- or TextBlob-labeled datasets as the “ground truth” for fine-tuning language models, the limitations of these naive rule-based methods are baked into the models themselves. The result is a model trained on unreliable data, which ultimately produces unreliable outputs.
To address this problem, we first collected a large amount of text data from various crypto-related media sources, including news outlets and social media platforms like X (formerly Twitter) and Reddit. We ensured the dataset included diverse perspectives by capturing a wide range of opinions and sentiments. For labeling, we first used GPT-4 to label the data. Then, we manually reviewed the labels to ensure they are accurate and reliable. In total, we gathered around 100,000 data points. This high-quality dataset is the foundation of our sentiment analysis model.
Fine-Tuning Languages Models for Crypto Sentiment Analysis
After building a high-quality labeled dataset, the next step is fine-tuning various language models to see which one performs best for crypto sentiment analysis. We experimented with a mix of general-purpose and domain-specific models, each with unique strengths.
Domain-Specific Models
We started with crypto-related models like FinBERT and CryptoBERT, which are pre-trained on financial and cryptocurrency-related texts. These models are designed to understand terminology and nuances specific to their respective domains.
General-Purpose Models
We also fine-tuned several widely used BERT-based models:
- RoBERTa: A robustly optimized version of BERT that focuses on improving training techniques to enhance accuracy.
- DeBERTa: A powerful model that incorporates disentangled attention and enhanced mask decoding, achieving state-of-the-art performance on many NLP tasks.
- DistilBERT: A lightweight version of BERT, designed to be faster and more efficient while retaining much of BERT’s performance.
Further, we experimented with GPT-2, a generative model known for its flexibility in language tasks, and alternative architectures like ELECTRA (which uses a generator-discriminator approach for training) and XLNet (which focuses on better-capturing dependencies between words using permutation-based training).
Why Not Just Use GPT-4?
You might wonder why we didn’t simply use GPT-4 or similar proprietary models for sentiment labeling and prediction. While GPT-4 is a powerful tool, it comes with significant costs. By fine-tuning these open and freely available models, we can achieve high performance, better accuracy, better control with a much smaller model and without incurring ongoing usage fees.
Handling Class Imbalance
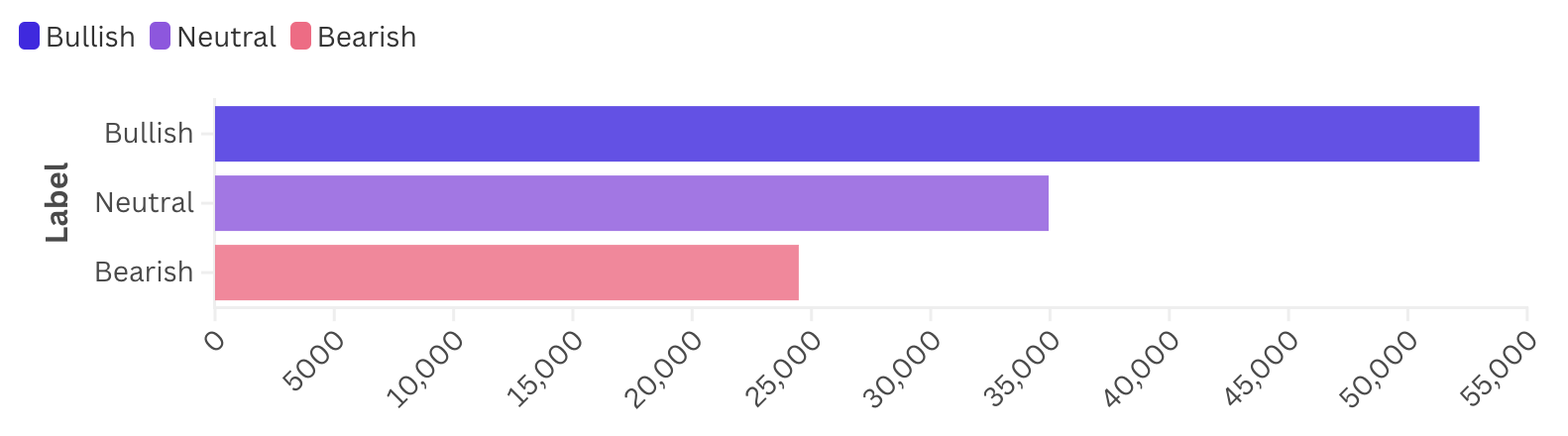
One issue we faced during fine-tuning was class imbalance in our dataset. In cryptocurrency discussions, especially on social media, there tends to be more bullish data (positive sentiment) than neutral or bearish sentiment (see chart below). This imbalance poses a challenge because the model might naturally favor the dominant class, leading to skewed predictions.
To address this, we trained a weighted model by assigning higher weights to underrepresented classes during training. The weights were chosen empirically by analyzing the distribution of labels in the dataset and inversely scaling the weights based on their frequencies. This approach helped the model achieve better balance and avoid favoring the dominant class, ensuring more reliable sentiment predictions.
Results
Surprisingly, domain-specific models like FinBERT and CryptoBERT didn’t perform as well as some of the general-purpose models. (I should note that the results from FinBERT and CryptoBERT are still very good.) Among all the models we tried, one of the DeBERTa models stood out, achieving an accuracy of around 87% on our dataset, which is better than most existing literature on crypto sentiment analysis.
This result came after extensive hyperparameter tuning, where we adjusted parameters like learning rate, batch size, weight decay, and the number of training epochs to optimize performance.
Now, we can feed text data into our model and it can output sentiment labels. This capability forms the backbone of our sentiment analysis pipeline, enabling us to process and quantify sentiment from diverse crypto-related media sources.
Building the Sentiment Analysis Pipeline
To turn raw text data into quantitative insights, we built a complete sentiment analysis pipeline. This pipeline processes data from various sources, labels it using our fine-tuned model, and aggregates the results to provide sentiment scores for each cryptocurrency. Here’s how it works

Fetching Text Data
The first step is to fetch text data from multiple sources in the crypto sphere, including multiple crypto news platforms, X (formerly Twitter), Reddit, and more. (We are continuously expanding our sources.) These platforms offer diverse perspectives, from expert opinions to social media chatter. Our system collects data periodically throughout the day, ensuring that we always work with the freshest market information.
To give you an idea of what our datasets look like, below are some snippets:
 | |
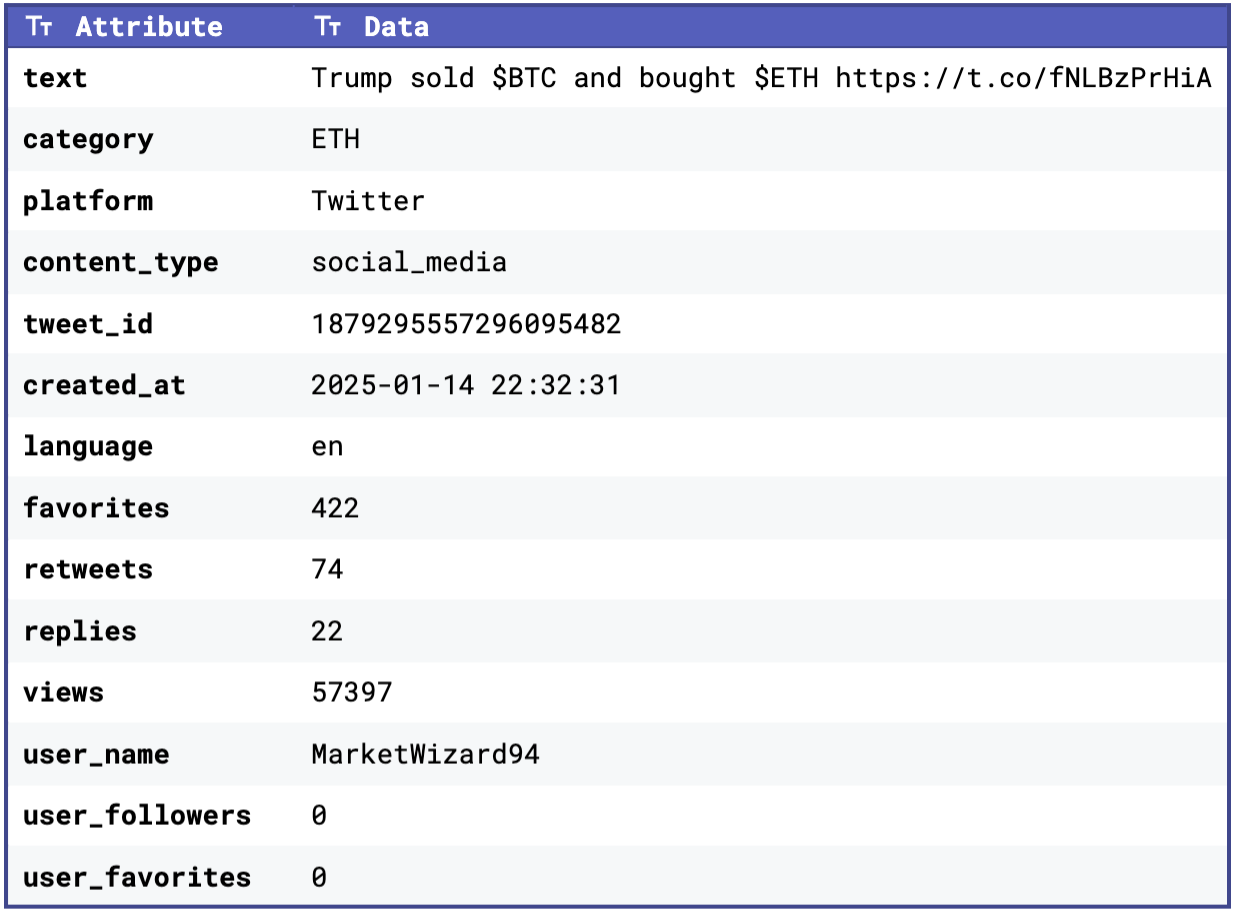 | 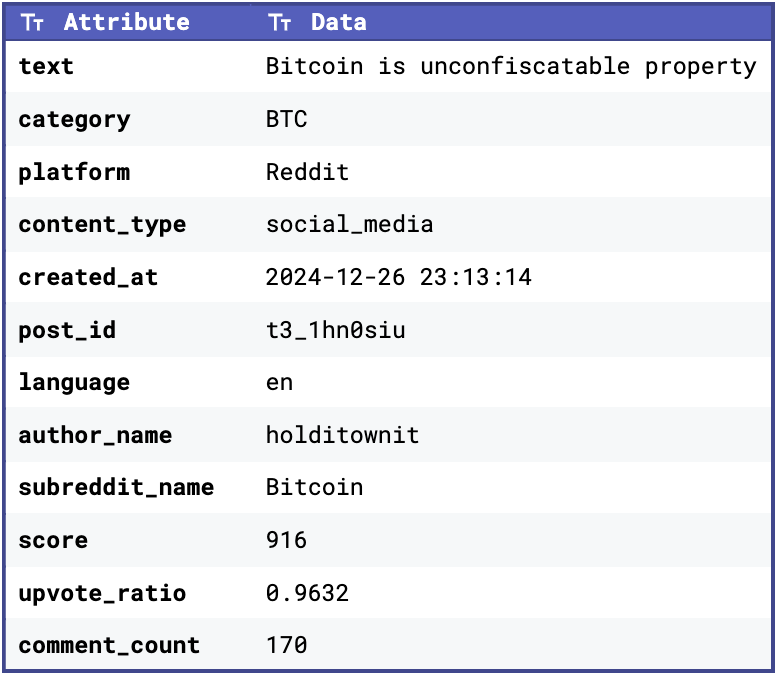 |
In addition to the raw text, we also collected platform-specific attributes, such as score, upvote_ratio, comment_count (for Reddit posts) and favorites, retweets, replies, and views (for tweets). These attributes help us assess the engagement and relevance of the content, which can be factored into our sentiment aggregation process.
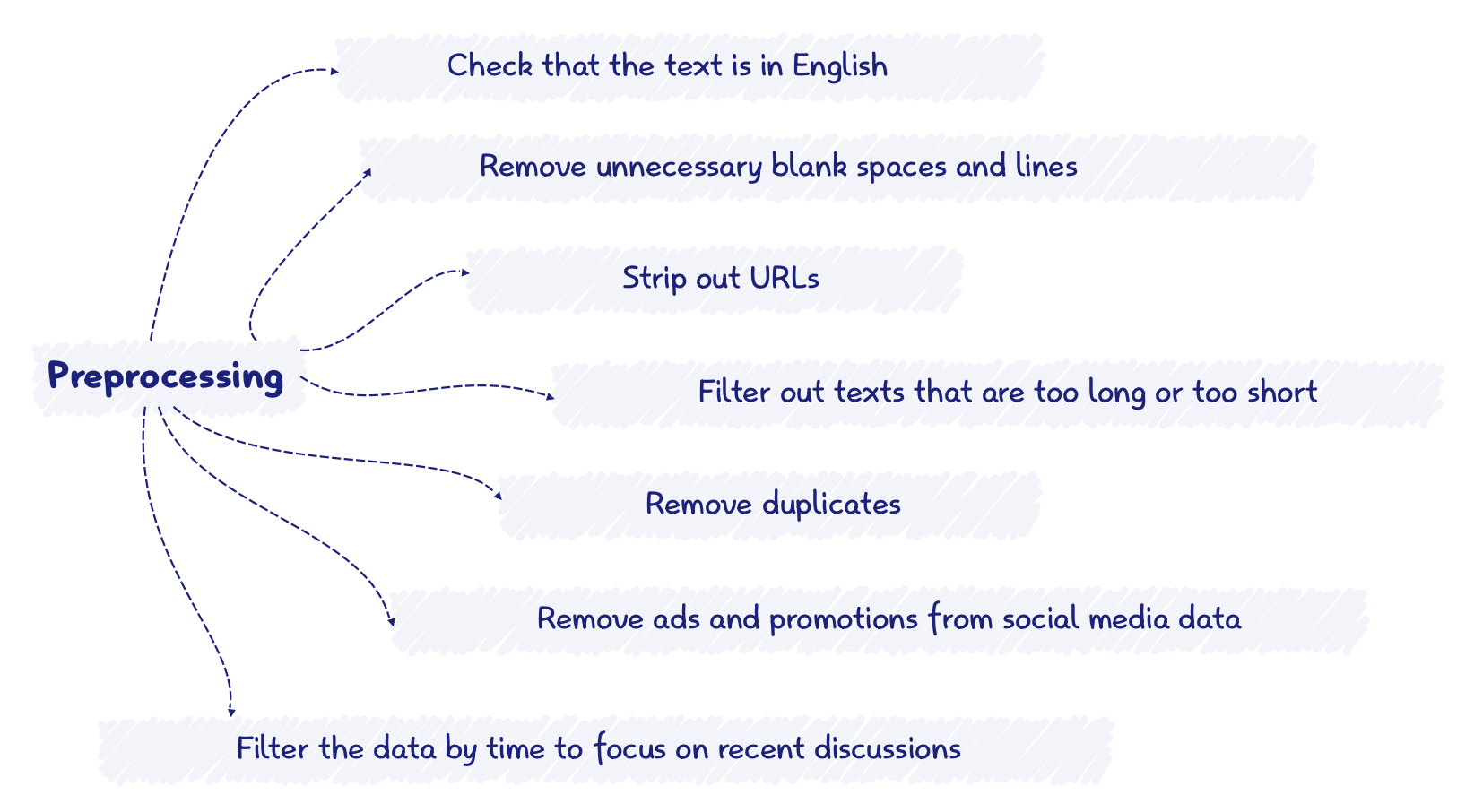
Preprocessing Text Data
Once all the media data is fetched, it goes through a preprocessing phase to clean and standaradize the text. Text data, especially social media data, is often quite messy. This step is important for ensuring high-quality input to our sentiment model. The below chart illustrates some of the steps we took to clean the data
Sentiment Labeling
After preprocessing, the cleaned text is fed into our fine-tuned sentiment analysis model. The model assigns a sentiment label to each text – bullish (1), bearish (-1), or neutral (0). This step converts raw, unstructured text data into quantifiable insights.
To show you an example, the chart below illustrates a real tweet before and after preprocessing, followed by its sentiment labeling:

Aggregate Sentiment Scores
Now for each cryptocurrency, we have many labeled text data with sentiment scores. The final step is to aggregate the sentiment scores across different media for each cryptocurrency. This involves combining sentiment data from news, social media, and other platforms to calculate a single, comprehensive sentiment score for each coin. While this final score provides a useful way to summarize overall market sentiment, it is something we are continuously testing and refining.
To ensure a balanced representation, we assign different weights to each media source based on its reliability and relevance. For example, news articles might be weighted more heavily than social media due to their typically higher level of credibility. This aggregated score represent the overall market sentiment for that cryptocurrency and can serve as a reference for trading activities.
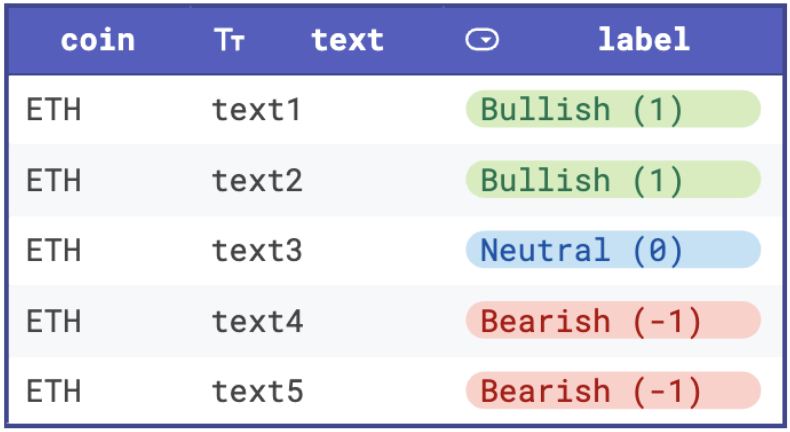
The final sentiment score would be be in the range of [-1, 1] where -1 is bearish and 1 is bullish. For instance, if we have a ETH text dataset with sentiment labels like in the table below, the aggregated sentiment score for ETH would be (1 + 1 + 0 - 1 - 1) / 5 = 0 here. This indicates that the overall market sentiment for ETH is currently quite neutral.
Wrapping Up
Through this project, we’ve built a robust sentiment analysis pipeline tailored to the cryptocurrency space. By combining high-quality data collection, advanced preprocessing techniques, and fine-tuned language models, we can transform unstructured text into actionable sentiment insights. This tool not only provides traders with a comprehensive view of market sentiment but also saves them the time and effort of manually sifting through multiple media sources. With the ability to analyze and aggregate sentiment across various platforms, we’re offering a powerful solution to help users make more informed decisions efficiently. This is just the beginning, and we’re excited to continue refining and expanding this system to deliver even greater value to our users.
Read more

A Tale of Gas and Approximation (part 1)
Embark on a journey exploring Gas on Starknet to build the AVNU gas approximation model
Dec 22nd 2023
A Tale of Gas and Approximation (part 2)
An in-depth analysis of Uniswap V2 gas consumption on Starknet
Dec 22nd 2023
A Tale of Gas and Approximation (part 3)
The final chapter of our gas exploration ending with the analysis of Uniswap V3 and a few words on generalized gas functions
Dec 22nd 2023
Copyright ©
2025 -
AVNU. All rights reserved.